
Fair Use Face-Off
It's the New York Times vs OpenAI in a Copyright Clash that has the potential to reshape the AI industry


One of the most important stories of 2023 broke in the final few days of the year. In that lost week between Christmas and New Years, where we all struggle to remember what day of the week it is, The New York Times sent ripples through the worlds of journalism, law, and artificial intelligence by suing OpenAI and Microsoft over AI use of copyrighted work. While foundation model companies like OpenAI have been dealing with simmering discontent from smaller creators and a flurry of copyright lawsuits since the launch of ChatGPT in late 2022 kicked off the industry-wide chatbot frenzy, this is the most formidable legal challenge thrown their way to date as The Times becomes the first major American media outlet to sue them. Overnight, their opposition side has morphed from a fragmented, amorphous group of individual actors into a unified, deep-pocketed, and highly credible global media outlet fighting for its survival in a rapidly changing world.
The lawsuit claims that OpenAI's generative AI models, such as GPT-4, were trained using content from The New York Times without proper licensing or payment. OpenAI has responded by asserting that using publicly available data for training AI models, including articles from The New York Times, constitutes fair use. And so, the core issue in the NYT vs OpenAI lawsuit - and by extension the broader debate around copyright concerns with GenAI training practices - ultimately boils down to how you define this deceptively straight-forward term: Fair Use.

The New York Times' claim of copyright infringement against OpenAI, despite their content being publicly available, is grounded in the nuances of copyright law which protects original works of authorship, including literary works like articles, from being used without permission in certain ways. Even if a work is publicly available, it doesn't mean it's free to use in any manner. The copyright holder (in this case, the NYT) has exclusive rights to reproduce, distribute, and display their work.
OpenAI's defense is based on the concept of "fair use," which permits limited use of copyrighted material without permission for purposes such as criticism, comment, news reporting, teaching, scholarship, or research. OpenAI would argue that their use of publicly available content for training AI models falls within this fair use exception.
The Times, however, contends that OpenAI used its articles not just for reference or analysis, but to train AI models that could potentially replicate or replace the need for original NYT content, thus affecting its market value. This goes beyond mere access to publicly available information and delves into the realm of reproduction and creation of derivative works.
The legal landscape around AI and copyright is still evolving. Fair use assessments are highly fact-dependent and vary from case to case. Let’s look at a few high-profile cases in recent memory:
Stability AI Lawsuit: Artists sued Stability AI for allegedly using their copyrighted images to train AI models, creating new images without permission. The plaintiffs also claimed that this approach not only deprived artists of potential earnings but also enabled the defendants to monetize the artists' copyrighted works for their own profit. However, the court was skeptical about the claims, noting the AI-generated images weren't substantially similar to the plaintiffs' art, and the vast number of images used in training (‘“five billion compressed images”) made direct infringement unlikely. This suggests for NYT vs OpenAI, the court may focus on whether AI outputs are substantially similar to the original copyrighted material.
GitHub Lawsuit: Programmers sued GitHub, claiming that the licensed code they published on GitHub’s website was used without permission to train its AI-powered coding assistant, Copilot. GitHub contended that the plaintiffs couldn't prove their specific code was used inappropriately, as Copilot's output is not a direct reproduction but rather unique coding suggestions based on learned patterns from reviewing open source code. The court dismissed privacy claims but kept open the possibility of injunctive relief based on property rights. This highlights the potential focus on specific use and transformation of copyrighted material in AI training, which could influence the current case.
The NYT lawsuit specifically alleges that OpenAI used its content without permission to train its AI models, which then directly compete with the NYT's services. This is slightly different from other cases, like Andersen v. Stability AI and Doe v. GitHub, which focused more on the reproduction of copyrighted works (visual arts and code, respectively) and the generation of potentially infringing outputs by AI models. Also, the NYT lawsuit deals with journalistic content, which may have different considerations compared to artistic images or software code in terms of its creative vs. factual nature.
The two most impactful exhibits from the lawsuit, in part, preemptively address defenses that have worked in previous cases.
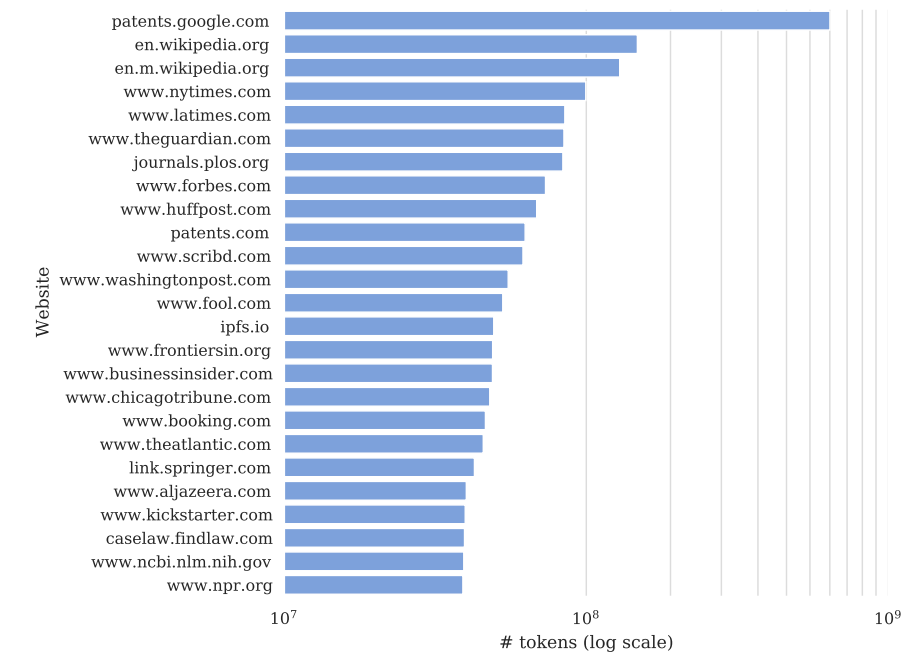
In response to the contention that vast amount of data may have been used in training which makes it hard to draw a connection to NYT directly, the lawsuit notes that the most highly weighted dataset in GPT-3, Common Crawl, is a “copy of the Internet” wherein www.nytimes.com is the most highly represented proprietary source (and the third overall behind only Wikipedia and a database of U.S. patent documents).
In prior rulings, the courts seem to focus on whether the AI-generated content is substantially similar to the training material and whether the entire or a substantial part of the copyrighted work is used by the AI. The transformative nature of the AI's use of the works is also a crucial factor. Previous case law, like the Supreme Court's decision in Google v. Oracle, suggests that using collected data to create new works can be seen as transformative and thus fall under fair use.
Anticipating the pushback that ChatGPT does not reproduce or copy, but only learns from historical patterns, the lawsuit shares many examples of a ChatGPT prompt response compared with the actual text from NYTimes. Since the lawsuit dropped, OpenAI, however, has directly addressed this regurgitation problem, contending that the prompts were intentionally manipulated and the regurgitations are primarily for years-old articles that have since proliferated on multiple third-party websites. They, however, also note that preventing this model behavior is a big priority for them.
This case is more than just a legal dispute; it's a defining chapter in the story of technology and intellectual property rights. The ruling in this case is likely to set a precedent that informs all subsequent activity in this space and decides which party holds more leverage in this fraught dynamic. This balance of power will ultimately influence what kind of revenue/profit sharing arrangements or licensing deals AI companies will cut with content creators. The outcome of the NYT vs OpenAI lawsuit promises to be a pivotal moment, potentially reshaping the landscape of copyright law and AI. I will be watching closely, in case you’d like to follow along. :)

deceptively straight-forward term: Fair Use. Well said.
'Fair' can often turn into painful debates between most rational parties. The vested interest here and the high stakes makes this so much more intense.