
Gemini Goes Deep
The AI race is splitting into fast chat and frontier cognition


After Anthropic and OpenAI dropped new frontier models last week, the collective timeline instinctively turned to Gemini: “Your move.”
The fact that this cadence now feels normal is its own story. Twelve months ago, a frontier release was an event. Today, if a lab goes seven days without shipping a benchmark breakthrough, it feels like radio silence. Humans recalibrate fast. The Overton window for “absurd” has moved substantially.
Yesterday, Google finally answered with a benchmark sledgehammer: an upgraded Gemini 3 Deep Think.
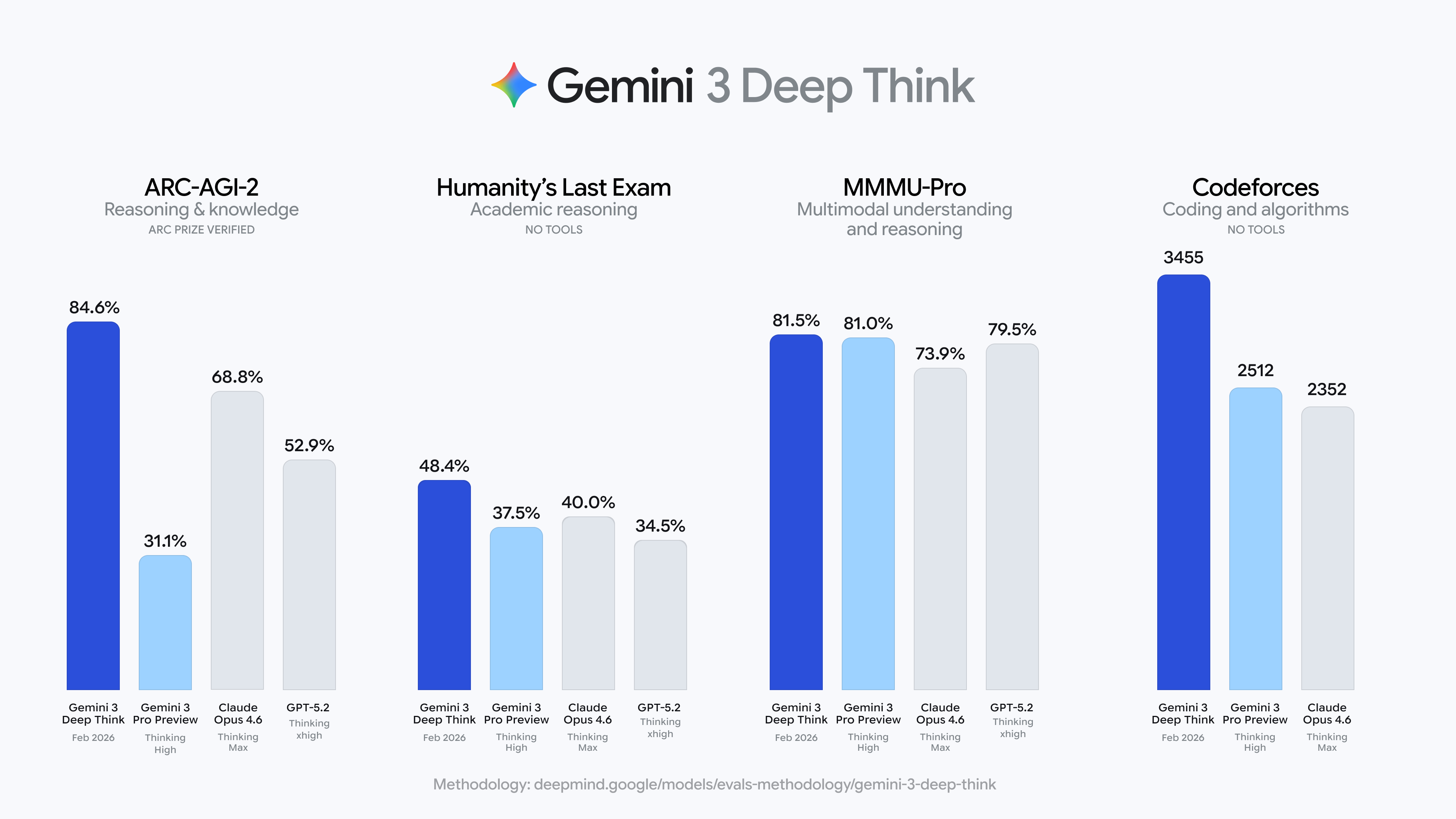
Even for those of us numb to benchmark theater, these scores are wildly impressive:
48.4% on Humanity’s Last Exam (without tools)
84.6% on ARC-AGI-2
Codeforces Elo 3455
Gold-medal-level performance across math, physics, chemistry olympiads
Some thoughts about this moment in time:
Consumer models are now good enough
All frontier models are now good enough for consumers. They write your memo. They debug your code. They summarize your 40-page PDF.
The marginal delta between labs still matters but we are no longer debating existential usability gaps. For the median user, intelligence is abundant.
So naturally, competition has shifted away from capability sufficiency and toward capability extremity. When everyone can run a marathon, the race moves to ultramarathons. From “Can it help?” to “Can it discover?”
Gemini is productizing “slow thinking”
Deep Think is framed around deliberate, multi-step reasoning and framed around depth, not speed. Most of the consumer AI race has been about latency, multimodality, vibe but for certain classes of problems - open-ended research, proofs, experimental design - speed is a liability. You want the model to think longer. This mirrors how humans operate at the frontier: intuition is fast; discovery is slow. Google is building Deep Think for discovery.
A natural bifurcation is emerging
Deep Think isn’t being sprayed across free tiers. It’s gated - Ultra subscribers, early access API applicants. Google is treating high-end reasoning as critical infrastructure, not a commodity endpoint. We’re watching a natural bifurcation emerge:Fast, broadly available models for general productivity
Slower, deeply capable reasoning engines for science, engineering, and high-stakes domains
Two tiers of intelligence. Two markets.
You don’t use a supercomputer to write a grocery list. And you don’t use a chat-tuned model to test a new materials fabrication pathway.The competition has moved from chat to cognition
Early LLM competition centered on sounding intelligent. Now the question is: “Can it reason through ambiguity, explore multiple hypotheses, and sustain long chains of structured thought?”
The top rung of models can now identify flaws in peer-reviewed math papers, design experimental fabrication processes, and operate at olympiad levels across disciplines. Chat competition is so 2025. The labs are racing to automate cognitive labor at the frontier of knowledge creation.
All three labs are now converging on the same axis: depth of reasoning over surface fluency. The cadence feels insane because it is. But the direction is even more telling. We are shifting from models that talk convincingly about the world to models that can interrogate it.