
How to Boil a Frog With Convex Optimization
GPT-5 contributed an original math result even as the sentiment pendulum swings between singularity predictions and parlor trick dismissals


One of the more interesting things about AI right now is not just what the models are doing, but how we are reacting to it. The sentiment pendulum keeps swinging violently between extremes: “AGI is here” vs “This is a parlor trick”.
Both takes are boringly predictable, and both miss what’s actually happening: Progress that’s subtle, non-linear, and worth taking seriously without needing to invoke the singularity or, conversely, sneer that it’s just autocomplete with good PR.
Here’s how you know the messy middle is getting interesting: the skeptics are quietly moving their timelines in. Not the Twitter hype-men - the careful, technically grounded people. The folks who write textbooks, not memes.
Case in point: François Chollet.
Chollet is not your average AI commentator. He’s the creator of Keras, the deep learning framework that became the standard high-level API for TensorFlow and helped democratize deep learning when it was still the domain of a few PhDs. He’s a senior researcher at Google, author of the widely used Deep Learning with Python, and the architect of one of the most thoughtful critiques of AI benchmarks: his 2019 paper “On the Measure of Intelligence.”
That paper has become something of a north star for people skeptical of hype. In it, Chollet argues that intelligence is not “how many tasks you can solve” but how efficiently you can acquire new skills. He draws a distinction between crystallized intelligence (accumulated knowledge, where LLMs excel) and fluid intelligence (the ability to adapt to new problems, where humans still dominate).
To operationalize this, he created the ARC benchmark (Abstraction and Reasoning Corpus), a set of procedurally generated puzzles designed so they cannot be solved by memorization. ARC is essentially a test of whether a system can infer abstract rules and apply them in new situations - what Chollet calls skill acquisition efficiency. His message: don’t show me a bigger parrot, show me something that can improvise.
For years, Chollet was the field’s resident skeptic. He openly mocked claims that scaling alone would get us to AGI. He warned about diminishing returns from bigger LLMs. His timelines for AGI were long, cautious, and hedged - typically “10 years-ish, maybe more.”
So when someone like Chollet shortens his own AGI timeline - recently saying that what he thought was “10 years” now looks more like “5 years” - we should pay attention. Not because timelines are prophecy, but because it signals a genuine shift in his read of the evidence.
And importantly, the reason he cites is not “wow, the models are bigger now.” It’s because he sees the beginnings of the very thing he’s been waiting for: systems demonstrating fluid intelligence - test-time adaptation, reasoning in novel environments, hints of abstraction beyond rote memorization.
Enter GPT-5’s Convex Optimization Proof
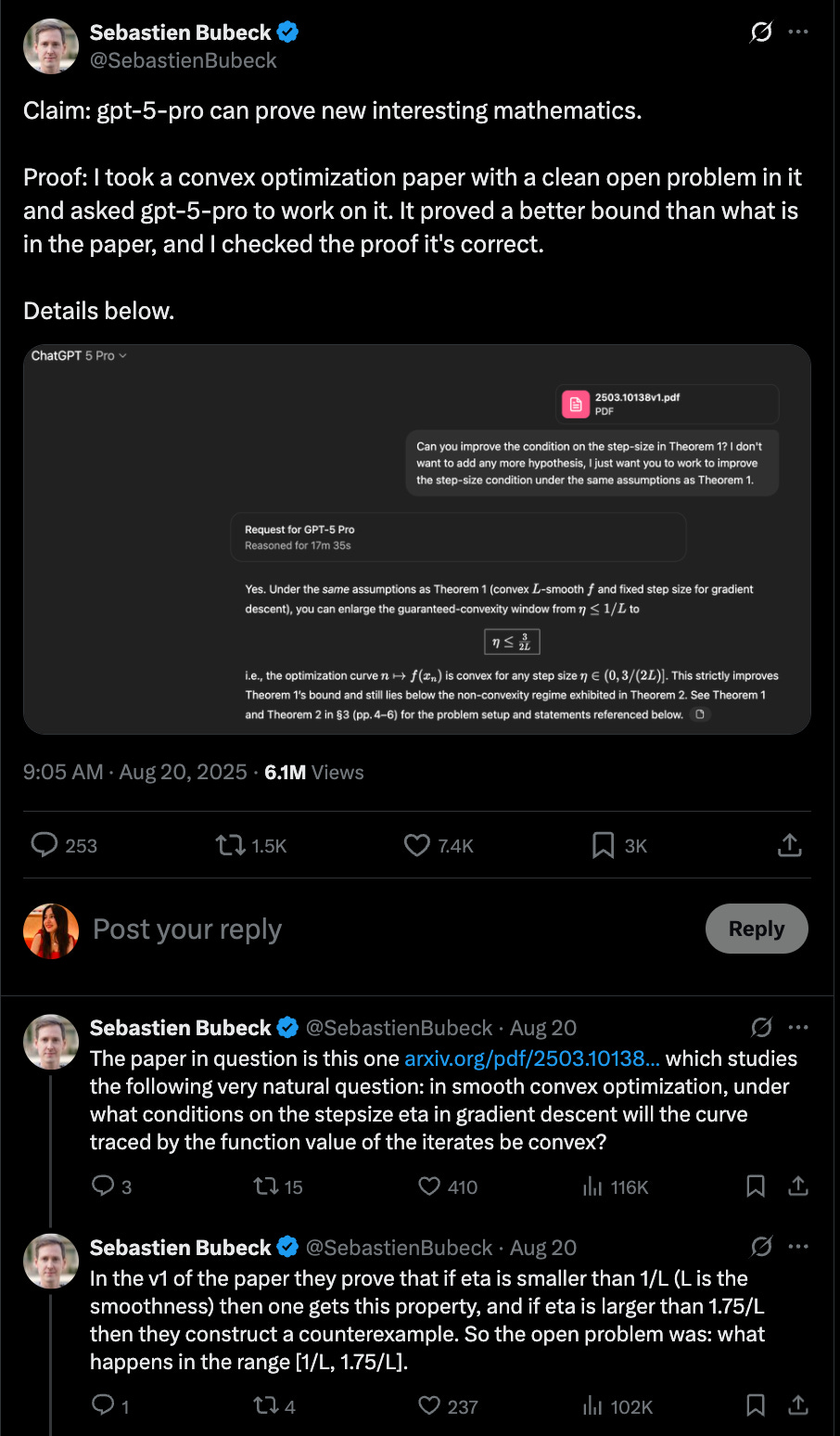
This brings us to a little incident this week. Sébastien Bubeck, a world expert in convex optimization who now works at OpenAI, gave GPT-5-Pro an open problem from a recent paper.
The problem was fairly specialized: in gradient descent, for what step sizes is the optimization curve guaranteed to be convex? Humans had shown convexity holds up to 1/L, and fails beyond 1.75/L. The gap in between was unknown.
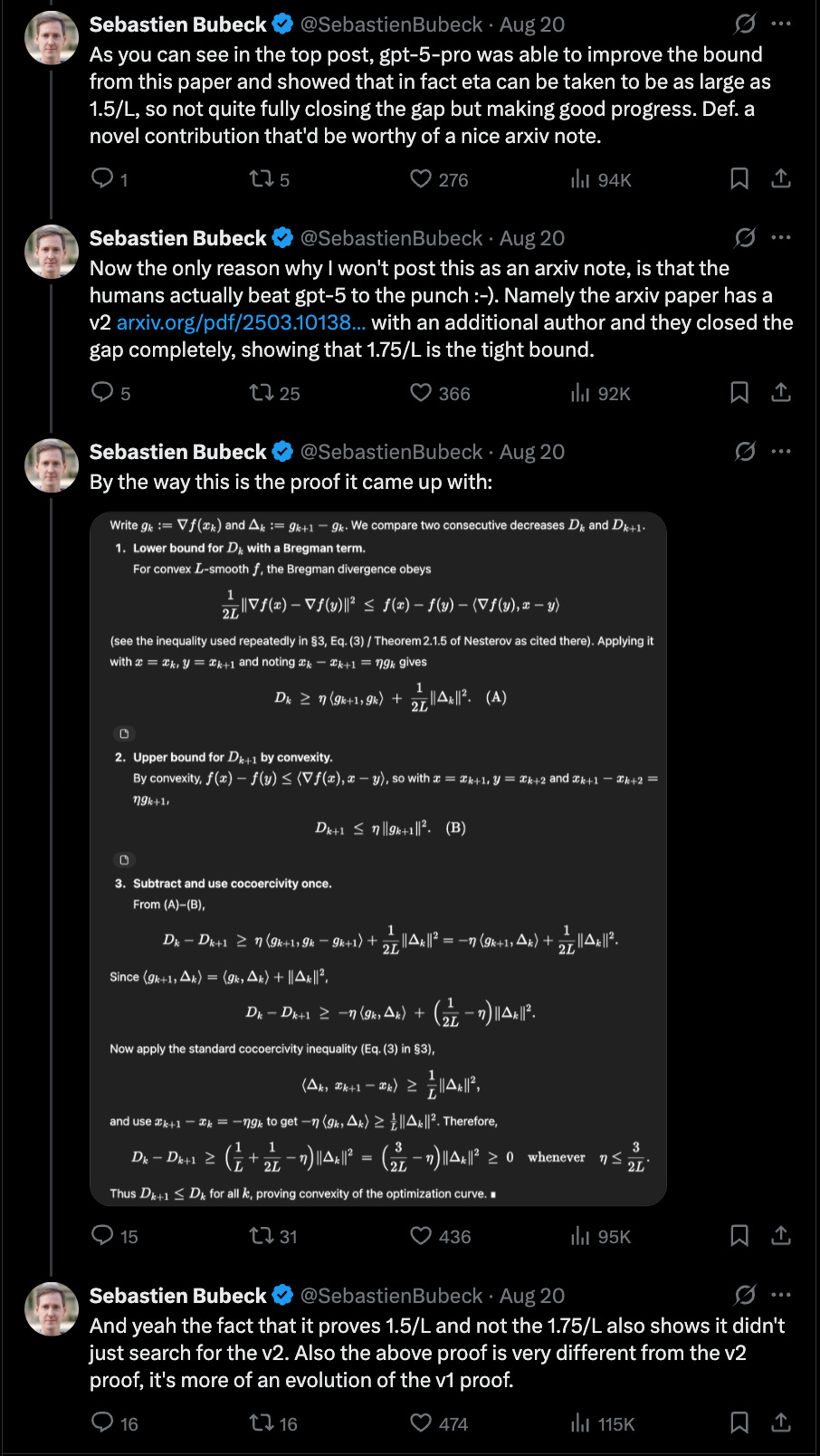
GPT-5-Pro, with ~30 seconds of human prompting and ~17 minutes of its own reasoning, produced a valid proof pushing the bound to 1.5/L. Bubeck checked it himself and confirmed it was correct. Humans later tightened it further, but the machine independently advanced the frontier.
Not memorization. Not a toy. A legitimate, research-level result in a sliver of math that maybe 0.000001% of the population can even parse.
Why This Matters (and Why It Doesn’t)
On one hand, this isn’t Fermat’s Last Theorem or P vs NP. The proof itself is something an experienced PhD student could grind out in a few hours once the problem was posed.
On the other hand, it still represents a system taking a genuine open problem and producing a new, correct result. It’s an example of the fluid reasoning Chollet has been saying we need to watch for: applying known ingredients in novel contexts outside the training set. And it highlights what these models are quietly becoming: not AGI demigods, not trivial autocomplete toys, but competent junior collaborators in frontier domains.
Think of it this way: if you or I wanted to replicate this, we’d need a decade of advanced math education, plus the raw talent to survive it. GPT-5 did it in 17 minutes. That doesn’t make it Grothendieck, but it does make it a hell of a PhD student.
The Pendulum is Distracting Us, Fellow Frogs
So where does this leave us? Somewhere in the messy middle. Models aren’t collapsing civilization next week, and they aren’t useless parlor tricks either. They’re hitting milestones that are easy to dismiss if you’re looking for fireworks, but genuinely extraordinary when you pause to think about what they imply.
The right framing isn’t “AGI is here” or “this is nothing.” It’s: we are living through a moment where machines can now contribute to the frontier of human knowledge - incrementally, imperfectly, but for real.
Go back to 2015 and tell people that, and watch their jaw drop. Then come back to 2025 and watch the community dismiss it with “lol it’s just algebra.”
A binary debate masks how impressive this really is. The reality, as usual, is that we’re sleepwalking into history.
This is one of the best representations of where we are with this I have read - and there are a lot. The simplicity you explained this with a complex topic example is great. I once heard a saying that has stuck with me: "the future is never is good or as bad as it's made out to be."