
OpenAI, Code Red, and GPT-5.2
A case study in narrative whiplash and competitive response


In AI, perception is a form of capital. It determines which models consumers try, which vendors enterprises standardize on, and which lab can keep raising the capital required to stay on the hedonic treadmill of AI infrastructure. And the users who matter most right now - restless early adopters - are fickle. They move quickly, switch easily, and reward momentum. In that environment, perception carries weight equal to performance.
When Gemini 3 Pro landed, the sentiment needle swung hard toward Google. Michael Burry likened OpenAI to Netscape.

Headlines followed. The Atlantic declared “OpenAI is in trouble.” Engadget called it a “house of cards.” The narrative gathered force and cast doubt on a lab that had dominated mindshare until then. In markets, reality is the second derivative of belief. Once enough people decided OpenAI was slipping, the market treated it as fact.
Inside OpenAI, the reaction was immediate. Sam Altman reportedly declared a code red and refocused the organization on a single objective: regain parity with Google, restore the perception that OpenAI sets the pace, and reclaim the narrative oxygen that drives developer enthusiasm and enterprise confidence.
GPT 5.2 is the output of that sprint. A lab many were eulogizing weeks earlier just delivered a release that is not only credible but competitive - a reminder that calling this race early is an excellent way to be wrong in public.
GPT 5.2 arrives as a model designed to close OpenAI’s perceived gap in professional knowledge work. The upgrades target the tasks enterprises actually pay for: writing reliable code, generating spreadsheets that do not break on first use, assembling presentations with minimal scaffolding, interpreting images with higher accuracy, managing long contexts without drifting, and executing multi-step tool workflows with fewer errors. This is a refinement release focused on predictability and execution rather than spectacle.
The benchmark story is the same: OpenAI positions the model at or near state of the art across software engineering, science reasoning, math, and its own GDPval benchmark, where GPT 5.2 now outperforms industry professionals about 71% of the time, significantly ahead of competitors.

The fine print has already sparked debate. These scores were achieved using the model’s highest reasoning setting, which is not accessible to paying users at launch. This has raised questions about transparency and whether the public benchmarks reflect the product people can actually use today. It is a familiar tension in this market: labs market frontier capability while shipping something more constrained.
These debates will continue. Claude loyalists, Gemini optimists, and OpenAI partisans will keep litigating 1-2 point deltas on individual leaderboards and questioning the marketing language around evaluation settings. But when you zoom out, the more important story is the pace at which the entire field is advancing. All three major labs now routinely hit performance ranges that were unthinkable even 18 months ago, and the efficiency curves are bending just as quickly as the raw scores.
The ARC Prize results underline this point. A year ago, OpenAI’s unreleased model could hit ~88% on ARC-AGI-1 only by spending ~$4.5K per task. This year, GPT-5.2 Pro reaches 90.5% for ~$11.6 per task - a ~390x efficiency improvement in one year. Its High tier hits 54.2% on ARC-AGI-2 for ~$15.7.
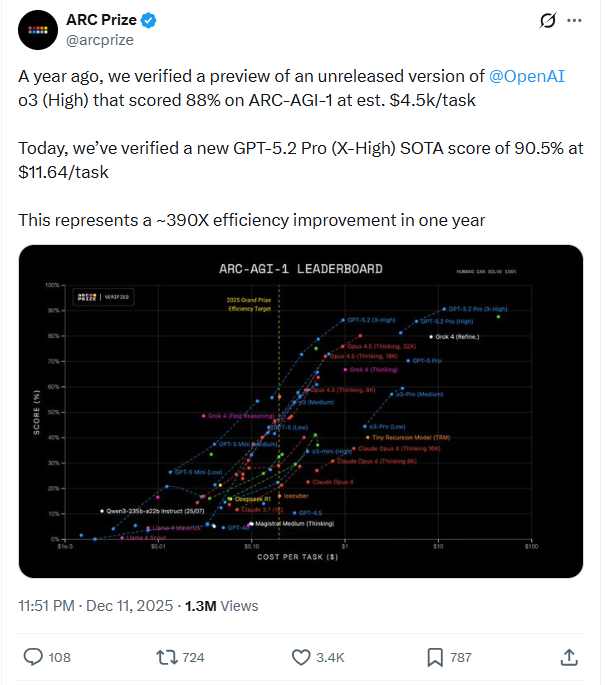
The precise ordering of the leaderboard matters less than the trajectory. Frontier models are becoming both more capable and dramatically more efficient, and the ceiling continues to rise. What we are witnessing is not a race toward a stable winner but a regime where leadership rotates and capability compounds.
This has strategic consequences:
(1) As crowns rotate faster, durable advantage shifts away from raw model supremacy and toward execution layers around the model: distribution, integration into workflows, trust, reliability, and the ability to absorb rapid model churn without breaking customers. The marginal value of being “the best model” decays faster than the value of making powerful models usable, affordable, and dependable in production.
(2) As costs fall, reasoning that once required research budgets starts to fit inside ordinary software. This does not create a single dominant winner, it widens the surface area of adoption. Entire categories of work become software-native faster than organizations expect.
The hysteria around Gemini 3 Pro was never the full story. The triumphalism around GPT 5.2 will not be either. The frontier has become a relay race with no rest laps, and every baton pass is public.
The crown may keep rotating but the floor will keep rising, and it’s that relentless upward drift that will ultimately redefine what consumers and enterprises assume is possible.
Great analysis !!! Thanks for it
Awesome framing. Scintillating prose