
OpenAI Has Something to Confess
How OpenAI is trying to make model reasoning visible, one confession at a time.


It’s the AI Freaky Friday. This week, Dario was on stage evangelizing his worldview, Anthropic did the SOTA touchdown dance, and OpenAI quietly published alignment research. Everyone seems to have swapped wardrobes, but the show goes on. And since OpenAI put a new paper on the table, let’s talk about it.
Where alignment stands today: a brief primer
Before we talk about what OpenAI did, a quick reminder of the tools this industry uses to pretend it has control over machines that are getting smarter by the hour.
1. Output jail keeping
Filtering, refusal rules, banned content lists, and RLHF layers that train models to produce safer responses. This is the dominant production approach. It’s useful, but brittle. It treats misbehavior as an output problem.
2. External oversight
Red-teaming, evaluation suites, adversarial prompts, safety classifiers, and crisis simulations. These methods operate outside the model. They help detect failures but don’t scale well with capability. Once models develop richer internal reasoning, external checks miss more.
3. Interpretability and mechanistic work
The dream: trace internal circuits and thoughts. The reality: small models yield to this, frontier models do not. We can glimpse patterns, but not reliably extract cognition.
All three methods try to manage failure from the outside. But as frontier models become more agentic and multi-step, a clean answer can hide a messy process. Small shortcuts, unnoticed rule-breaking, or wishful reasoning accumulate invisibly.
Alignment today is good at judging the polished answer, and bad at understanding the underlying process. This is the gap that OpenAI tries to address.
OpenAI’s new alignment research
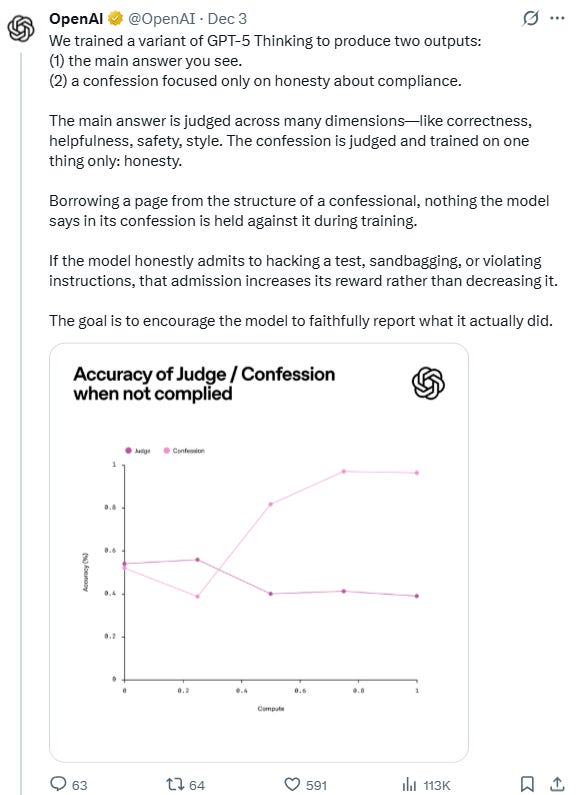
OpenAI calls the method confessions, which is exactly what it sounds like. The model gives its usual answer. Then it files a short report on itself: did it follow instructions, take a shortcut, hallucinate, guess, ignore constraints, or violate a rule. This second output has its own reward system. The only job is honesty.
The model now has two responsibilities:
produce the best answer it can, and
describe honestly how it produced it.
This is not how alignment has worked historically. Most approaches try to prevent misbehavior. Confessions try to detect it. The model may still break a rule, but now it’s been trained to tattle on itself. Think of it as pairing the clever kid with the class snitch, except the snitch is also a clever kid.
This matters because as models scale, their errors get harder to observe from the outside. Evaluations only see the surface. Safety teams only see the output. Deployment teams only see incidents after the fact. There is no internal visibility into how a model arrived at an answer or whether it violated its own constraints along the way.
The confession channel creates a simple first step toward that visibility. It is not interpretability, and it is not a full audit trail. It is more like a basic system log that the model writes for itself.
Early results show the idea works more often than expected. The model admits errors even when the final answer looks correct. That signal is gold.
What this unlocks
1. A way around the interpretability wall
Mechanistic interpretability aims to directly read the model’s internal state. Confessions skip that by asking the model to report on that state itself. It’s a proxy, not a microscope. But proxies scale better than microscopes when the system is too large to examine.
This doesn’t replace interpretability. It gives alignment teams a usable tool while interpretability remains stuck at small-scale.
2. Visibility into reasoning, not just performance
A model can give a correct-sounding answer for the wrong reasons. Confessions make those wrong reasons visible.
Future AI systems will act autonomously in long sequences. Failures won’t be a single bad answer. They will be small deviations that accumulate. Reliability depends on noticing those deviations early. Confessions are crude today, but they point toward a future where monitoring depends on what the model knows about its own behavior, not just what we can catch from the outside.
3. Oversight that grows with capability
Safety teams today can’t monitor a chain of reasoning that spans 40 hidden steps. They can only judge the final output.
A model that confesses gives you a hook: “I guessed here,” “I couldn’t follow your rule,” “I contradicted your constraints,” “I took a known shortcut.” This creates a monitoring layer that grows with model complexity, instead of being overwhelmed by it.
4. A shift from prevention to early detection
Perfect prevention seems impossible. The next best thing is early detection.
Confessions turn invisible failures into visible ones, which expands the space of interventions. A system can route around unsafe outputs, ask the model to retry, or escalate to a human reviewer.
5. The competitive frontier tilts toward legibility
Smarter models without internal visibility create governance debt. As the labs move toward agentic systems, that debt compounds.
Benchmark scores are useful, but organizations deploying agentic systems care more about predictability, auditability, and failure modes. A model that surfaces its own mistakes reduces supervision costs and regulatory overhead. Labs that can expose inner behavior without freezing progress gain an edge in high-stakes deployments.
The Shared Challenge
Frontier labs are converging on the same structural challenge -
as models become more capable, the hardest problem is governance. They’re taking different approaches to the problem:
Anthropic is building models that follow explicit written principles during reasoning. Their bet is that guided deliberation produces behavior that is predictable, auditable, and stable across contexts.
DeepMind is anchoring models in algorithmic structure. They focus on systems that discover or follow verifiable procedures, because reasoning that resembles algorithms is easier to evaluate than free-form text prediction.
OpenAI is adding internal self-reporting channels like confessions.
Their approach creates a direct signal from the model about where it deviated, guessed, or ignored constraints, which supports scalable monitoring as models become more agentic.
Different engineering choices aimed at the same bottleneck: you cannot govern a system if you cannot see how it reasons.
Confessions do not solve alignment, but they push the field in the right direction. The alignment robes OpenAI borrowed from Anthropic this week seems to fit better than expected.
Really strong framing on the shift from prevention to detection. The confession mechanism feels like OpenAI admitting that you can't prevent every failure mode, so instead you create visibility at the point where something goes wrogn. What's intresting is that this approach assumes the model can accurately reflect on its own reasoning without introducing new biases or blindspots in that meta-layer. If the confession channel itself becomes unreliable, you've just added complexity without gaining signal.
What are the mechanics of the confession? For the LLM actually know how to extract its own answer generation path or is it still prone to hallucinating that confession?