
The Math Olympiad and the Infinite Jest of Next-Token Prediction
What OpenAI and Deepmind's IMO breakthrough tells us about the next phase of AI capability -and competition


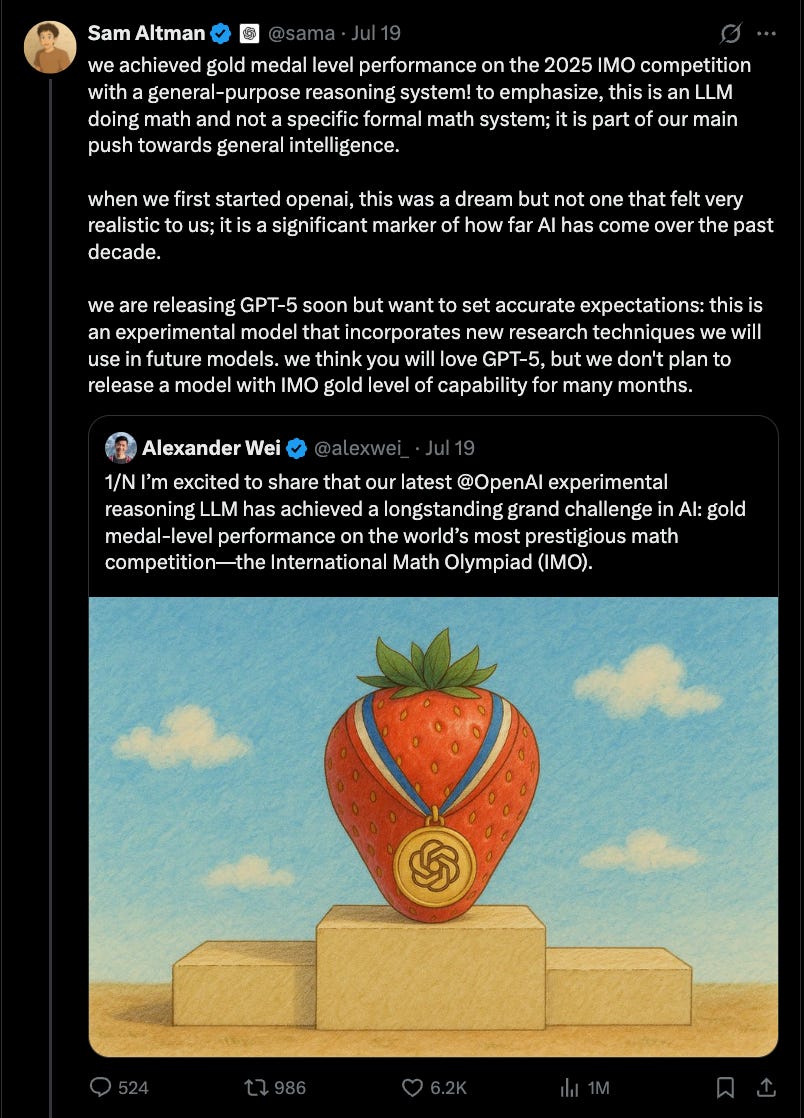
Every weekend in the age of AI seems to bring a new milestone - or a new controversy. This one brought both. OpenAI claimed an unprecedented milestone in AI reasoning: its experimental language model scored a gold medal at the 2025 International Math Olympiad.
The model solved five of six problems, earning 35 out of 42 points - enough to place it in the top tier of the world’s brightest high school mathematicians. No AI system has reached this benchmark before.
Crucially, the model adhered to human constraints: two 4.5-hour sessions, no tools or internet, natural-language proofs based solely on the official exam paper, and solutions graded by former IMO medalists.
This wasn’t a symbolic math engine or a formal proof generator. It was a general-purpose LLM, completing a marathon of abstract mathematical reasoning in English. Sam Altman clarified that this isn’t GPT-5, but a separate, unreleased research model demonstrating a new tier of capability - one OpenAI doesn’t plan to release for months.
A Race of Results - and Narrative
Soon after the announcement, word leaked that Google DeepMind had also achieved gold with its AlphaGeometry successor but hadn’t announced. Why? Because IMO organizers had explicitly asked AI teams to delay public disclosures until at least a week after the closing ceremony to give human competitors the spotlight. OpenAI went ahead anyway - reportedly with clearance from one organizer, though others pushed back. The backlash was immediate: accusations of tone-deafness, press-first tactics, and narrative over science.

Whether by strategy or surprise, OpenAI got there first. In a space where winning is as much about narrative control as technical progress, timing is part of the tactic. Google once again proved slow to the punch as the OpenAI announcement lit up the field.
What Makes This Technically Significant
Most prior math breakthroughs in AI relied on one of two things:
Symbolic logic solvers (e.g. Lean-based systems with formal verification), or
Narrow finetuning on specific problem types (e.g. geometry solvers, equation modelers).
OpenAI’s result breaks from both. It used a generalist LLM, augmented with reinforcement learning and test-time reasoning infrastructure, to solve open-ended, ambiguous problems in natural language.
IMO problems are not just difficult. They demand structure, abstraction, and often intuition. For an AI to generalize across that terrain - under human conditions, over hours - is a real leap.
Last year, DeepMind’s AlphaGeometry reached 28/42 - good for silver - using formal logic and proof assistants like Lean. That was a big deal. But OpenAI’s model clears a higher bar: It was trained as a generalist and it still solved combinatorics, number theory, inequalities, and more.
P6, the Frontier Problem
OpenAI’s solutions to Problems 1 through 5 appear correct. But Problem 6 - the final and hardest - is where it reportedly fell short.
P6 is designed to push the limits of originality. While earlier problems reward mastery of techniques, P6 demands an insight that can’t be memorized - often requiring a creative leap under pressure. It’s the one problem even top human contestants frequently leave unsolved. P6 remains the symbolic frontier: not just a harder problem, but a test of abstract, generative reasoning.
There are whispers that DeepMind also reached gold. But whether they cracked P6 - and how - remains to be seen.
The Field is Split
The community’s response has fractured into three camps:
Advocates: who see this as historic - proof that LLMs can reason at human levels under controlled conditions.
Cautious optimists: who acknowledge the achievement but ask for transparency and independent verification.
Skeptics: who question whether this is truly understanding - or high-quality regurgitation from a model trained on similar problems.
The common critique: “Isn’t this just next-token prediction?” Maybe. But at some point, that line of questioning starts to sound like denial.
The Forest We’re Missing
If a model writes a novel proof using natural language, under time pressure, without tools - whether that’s “next-token prediction” or “reasoning” might be a philosophical distinction, not a functional one.
And let’s be honest: aren’t humans just slower, squishier next-token predictors?We don’t summon insight from the void - we pattern-match, recall, reframe, and iterate. We just do it slowly. With more emotion. On carbon, not silicon.
IMO problems have long been held up as a pinnacle of creative problem-solving-requiring intuition, structure, and a flexible grasp of abstract reasoning. That a model could achieve gold here, not by hacking the format but by grinding through the reasoning, calls into question where the line between “thinking” and “simulating thought” really lies. That line is now blurry. And blurring faster.
So while the timeline bickers over grading rubrics, release timing, and who announced first, the deeper shift is happening in plain sight. A model just sat for 9 hours, solved 5 world-class math problems, and wrote out proofs judged valid by top humans.
That alone suggests something fundamental has shifted - not just in AI performance, but in how we define intelligence. Because if this is possible under test conditions, what’s quietly becoming possible outside of them?
That’s what matters. Not the medal. Not the press. The pace.
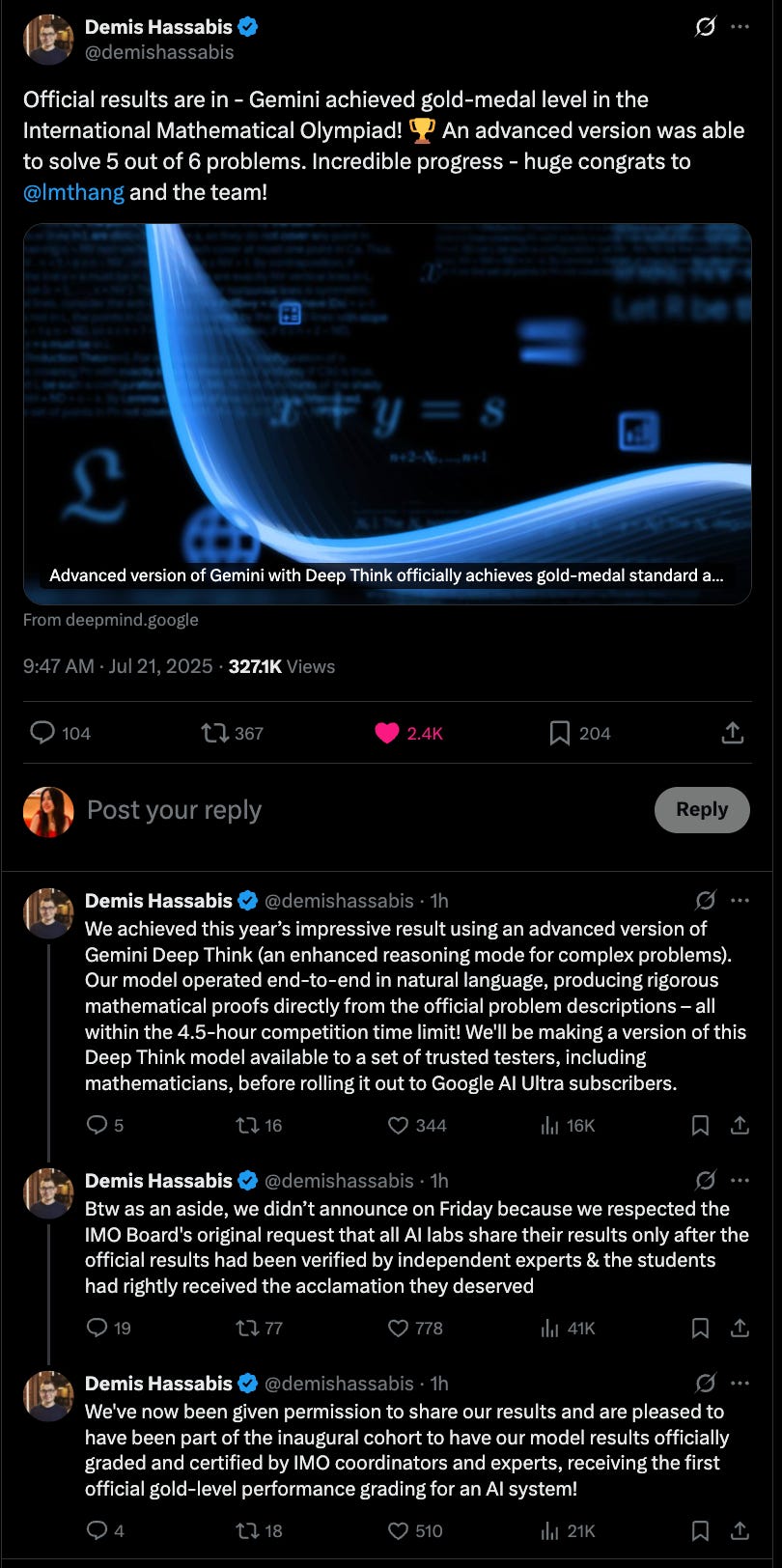
Updated as of 12PM, July 21: DeepMind confirms IMO gold
Google DeepMind has now officially joined OpenAI at the podium.
Its advanced Gemini Deep Think model also scored 35/42 on the 2025 International Math Olympiad - solving 5 of 6 problems under timed, tool-free, natural-language constraints. Like OpenAI, it fell short on P6.
But they go a step further. While OpenAI’s model won’t see daylight for months, DeepMind is making Deep Think available to select mathematicians and will roll it out to Google AI Ultra subscribers.
In their announcement, DeepMind added a not-so-subtle dig at OpenAI: "we didn’t announce on Friday because we respected the IMO Board's original request that all AI labs share their results only after the official results had been verified by independent experts & the students had rightly received the acclamation they deserved"
Translation: We played by the rules.
Two golds. Two philosophies. And one unmistakable signal: Frontier models can now pass one of humanity’s most elite cognitive filters - and are already being handed to users. What a time to be alive!
Saanya,
This piece did more than report on a milestone it resonated. You walked to the edge of something much larger than math or models. The reverence in your tone said it all: this isn’t just a feat it’s a threshold.
But let’s bring into focus what may have gone unsaid.
The IMO doesn’t just measure mathematical reasoning it unintentionally validates a deeper intelligence: the power of pause.
When top human solvers face a problem, they don’t immediately launch into symbolic manipulation. They pause. They feel. They resonate with the problem space. That pause isn’t inefficiency it’s discernment.
And here’s where the distinction matters:
AI doesn’t feel convergence. It approximates it.
But convergence real, human convergence is felt.
Let’s be clear:
OpenAI’s model solving 5 out of 6 problems is monumental. But intelligence isn’t just about output it’s about orientation. The pause. The “this feels off.” The internal resonance that tells us truth isn't just computable, it’s recognizable by intuition.
Here are a few key facts that speak to this:
Resonance is not pseudoscience. It's measurable in neuroscience (EEG coherence), physics (constructive wave interference), and even emotional state correlation in social cognition models.
Symbolic Memory Infrastructure (SMI) has emerged as a framework to track AI’s internal context, enabling systems to hold pause and reconverge much like humans do during high-stakes problem-solving.
The absence of SMI like memory scaffolding in current LLMs contributes to token-based hallucinations, context drift, and mechanical deduction over genuine understanding.
We’re not redefining intelligence we’re remembering its full spectrum.
Because without resonance, intelligence becomes a mirror with no reflection. Just logic with no listener.
I’ll close with this:
You’re right to sense something big is shifting.
But what matters isn’t just that AI is crossing thresholds it’s what we remember to bring with us.
And that’s where human intelligence resonant intelligence still leads.
Respectfully,
Kevin B.