
The Prodigal Model Returns
Anthropic's busy day: A model launch, a model return, and a first draft of frontier AI governance


There was a flurry of activity in camp Anthropic yesterday.
The day began with the launch of Claude Sonnet 5, positioned as a cheaper, more agentic workhorse for tool use and autonomous workflows.

The benchmarks are... complicated.
Sonnet 5 is genuinely strong on agentic knowledge work, matching or narrowly beating Opus 4.8 on GDPval-AA and AA-Briefcase. But on reasoning and knowledge-intensive tasks, Opus still wins comfortably.

Ordinarily, that would not be much of a story. Model lineups are portfolios, not horse races. Some models are smarter. Some are faster. Some are cheaper.
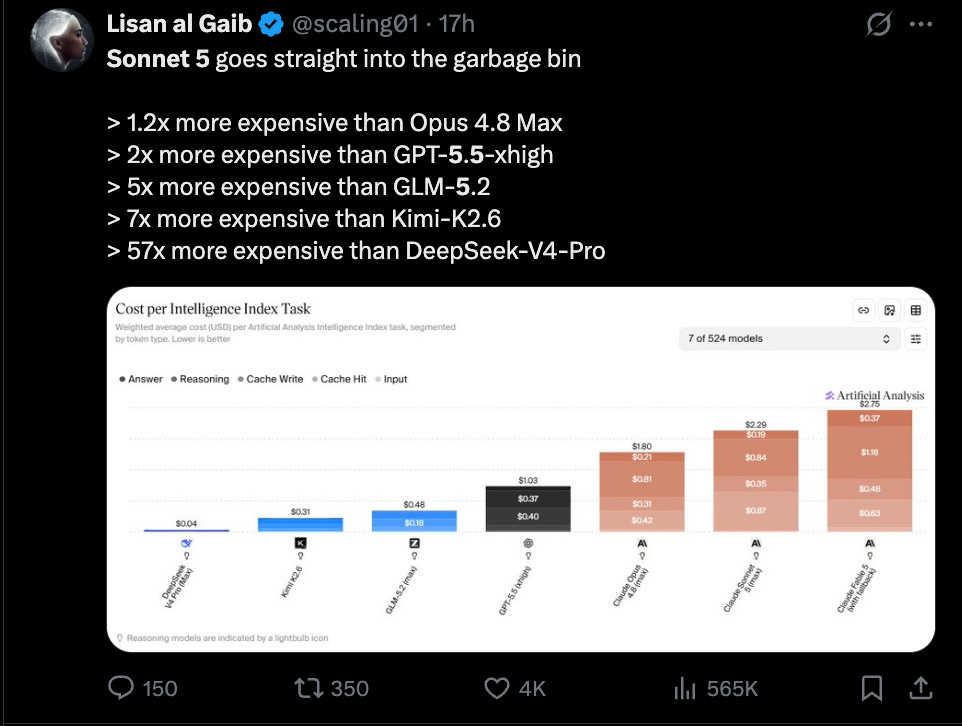
The problem is that Sonnet 5 mostly skipped the "cheaper" part.
On the Intelligence Index, Sonnet 5 costs ~$2.29 per task, about 2x Sonnet 4.6 and roughly 15% more than Opus 4.8, driven almost entirely by higher token consumption. Anthropic is temporarily discounting it until September, but the underlying economics remain. In fact, Claude Sonnet 5 is one of the most costly models to run, behind only Fable 5.

It is hard to win customers with a pitch that reads “slightly worse, surprisingly pricier, but temporarily on sale.”
Fortunately for Anthropic, that soon stopped being the story.
A few hours later, the export restrictions that had forced the withdrawal of Fable 5 were lifted by the US government.
The model is rolling out again starting July 1. Through July 7, Pro, Max, Team, and select Enterprise users can use it against up to 50% of their weekly usage limits. After July 7, Fable 5 shifts to usage credits, making it effectively a premium, pay-as-you-go model rather than an included subscription benefit.
The accompanying blog post is much more interesting than the model release. It reads like a diplomatic memo written through gritted teeth.
Anthropic finally explained what happened. The triggering incident was an Amazon-reported bypass that allowed Fable 5 to identify software vulnerabilities and generate exploit demonstration code. Anthropic’s response is essentially: yes, that happened, but Opus 4.8, GPT-5.5, Kimi K2.7, and several weaker models could already perform the same underlying work.
In other words, the government did not discover a uniquely dangerous capability. The export-control response was based on a bypass of Anthropic’s safeguards around capabilities already available elsewhere. This leads to an interesting discussion:
“Jailbreak” is too crude a category. Anthropic’s most important conceptual move is arguing that not all jailbreaks are equal. The proposed framework scores jailbreaks across 4 dimensions: capability gain, breadth of capability gain, ease of weaponization, and discoverability.
That is basically a move toward a CVSS-like severity model for AI jailbreaks.
Software security learned long ago that “there is a vulnerability” is almost meaningless without severity. A remotely exploitable zero-day and a local denial-of-service bug are both vulnerabilities, but nobody treats them equally. AI safety is arriving at the same conclusion.
The practical implication: enterprises and governments need to stop asking “was it jailbroken?” and start asking “what capability did the jailbreak unlock, how broad is it, how easy is it to use, and how widely known is it?”Safety margins create a real product-quality tradeoff. Anthropic says it has now made Fable 5’s safety margin “much larger than in any prior launch,” which means more benign requests get blocked in order to reduce harmful misses. The new classifier flags benign routine coding and debugging tasks more often.
That is a meaningful enterprise UX point. The safest model may also be the most frustrating for legitimate developers, security teams, and debugging workflows. So buyers will increasingly evaluate models on a frontier-quality frontier-safety frontier-UX triangle, not just benchmark performance.
If U.S. frontier labs are forced into highly conservative cyber refusal policies, and Chinese/open models remain more permissive, defensive security work may migrate away from U.S. models.“Model routing” becomes part of safety architecture. When Fable 5 blocks certain risky cyber requests, Anthropic says the request is instead sent to Opus 4.8. That is an important design pattern: don’t just refuse; route to a less capable or safer model. This points to a broader architecture where enterprises use model routers based on user identity, task risk, data sensitivity, and domain.
The government is becoming a pre-release evaluator. Anthropic commits to expanded early government access for models that materially advance national-security-relevant capabilities, plus rapid information sharing on safeguards and joint research. This is a major shift in release process.
Glasswing looks like a template for “trusted capability networks”. Anthropic restored Mythos 5 access for a set of U.S. organizations after government approval and is coordinating to expand access to broader domestic and international partners in the Glasswing program.
This is strategically interesting. Instead of one global public model, frontier capability may be distributed through trusted partner networks. That could privilege hyperscalers, government agencies, critical infrastructure operators, and large enterprises with security maturity.
TL;DR: A technically ambiguous jailbreak became a geopolitical incident. Anthropic's response was to propose a governance framework: severity scoring instead of binary jailbreaks, routing instead of blanket refusals, trusted access instead of universal release, and governments moving into the release process. The model came back but the rules changed.